|
|
ID是身份标识,生活中所涉及的每类业务都会有一个,身份证, 手机号, QQ号。那么问题来了,如何设计一个算法,能快速生成ID又能有效地避免冲突。往小了说,在存储领域每一行数据都会有一个ID,关系型数据库有 auto increment,非关系型数据库,如mongodb有自己的objectID 算法。对于各种ID我们可以简化为2类:1.去中心化,统一长度,规则占坑类, mongodb属于这一类, guid 属于这类。2.中心化,ID自增,auto increment属于这一类。
mongodb的ID规则
长度(byte)含义4unix epoch到当前的秒数3机器标识2进程标识3扩展计数
机器标识可以防止不同机器出现相同ID, 进程标识则可以在同一台机器上防止出现冲突。对于这种设计, 我想说 good! 无论是单机还是分布式都可以很有效地解决冲突的问题。
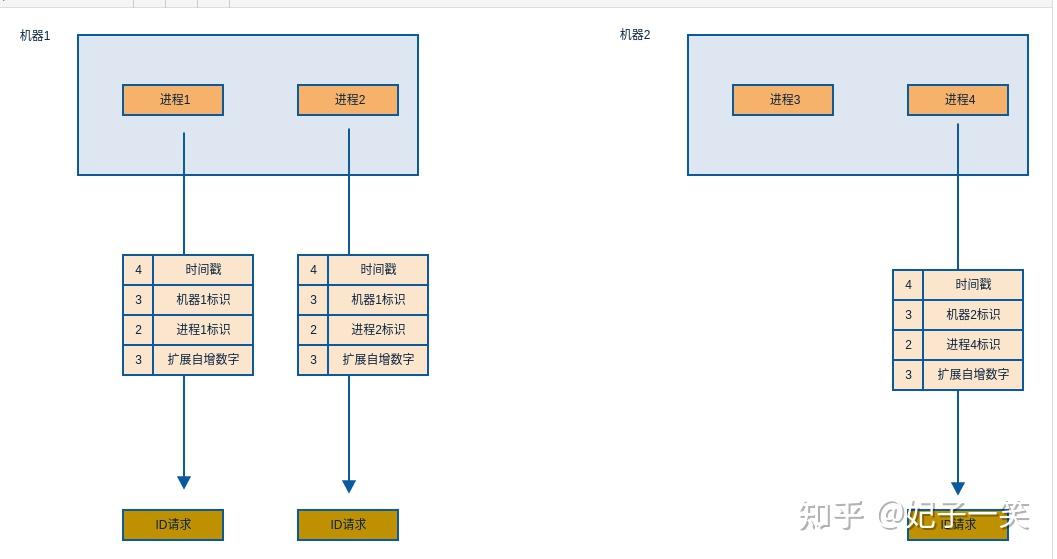
即使同一时刻有很多请求,不同机器也不会产生相同的ID,达到了去中心化的ID生成能力。
类似的设计还有twitter snowflake:
长度(bit)含义41unix epoch到当前的毫秒数10节点ID12sequence
也做到了不同节点去重,不同时间有序,只是把节点ID的制定交给了使用者。
相信大部分研发同学都使用过mysql,auto increment可以有效地解决ID生成。
CREATE TABLE animals ( id MEDIUMINT NOT NULL AUTO_INCREMENT, name CHAR(30) NOT NULL, PRIMARY KEY (id) );
id会从1开始自增,所以单台Server的情况下是不会有冲突的可能的。
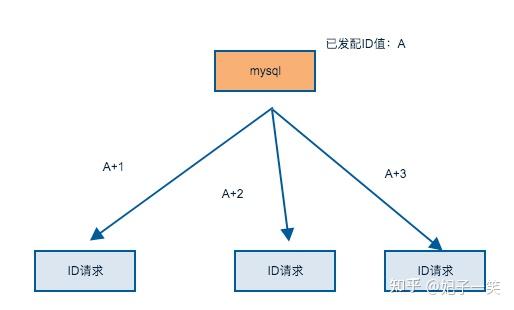
这样的设计一度非常常见于各种前端技术,用过LAMP技术栈的同学应该记得,目前仍被mysql, redis等广泛使用。
第一种方案是于空间时间相关的,类似于身份证

把坑给你空好,生成机制设计好,生成ID就变成了按机制生成数字填坑, 只要时间不停摆,人口不会短时间内爆增,这个ID就很难重复。等于把冲突保障交给了系统。
第二种方案与时空无关,只要生成器还在,就可以一直生产数据,冲突由生成器保障。
以mongodb为例
长度(byte)含义依赖4unixepoch到当前的秒数系统时间3机器标识2进程标识3扩展计数
如果因为操作不当,人为把机器的当前时间修改成过去某个时间,其新生成ID的时间部分就有可能相互冲突。
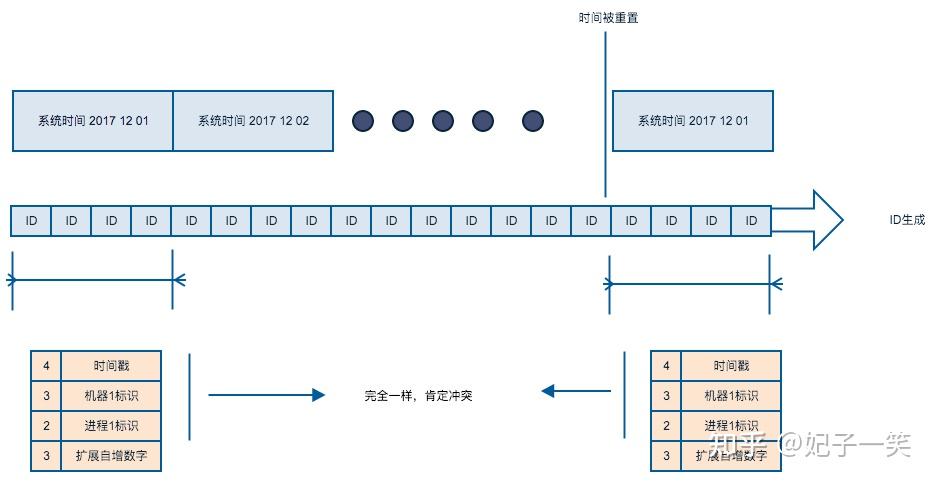
举例来说,某一年的公历出现了润8月(不可能出现),则8月出生的小朋友就要身份证重号了,现终于知道为什么身份证不使用农历了吧,哟呵呵。
自增形式的生成器很可能成为瓶颈,争对单点的问题业界已经有一些方案,比如分片自增
有3个节点 p1, p2, p3, 生成的ID规则:
p1: 1,4,7,10,13,16,19,22
p2: 2,5,8,11,14,17,20,23
p3:3,6,9,12,15,18,21,24
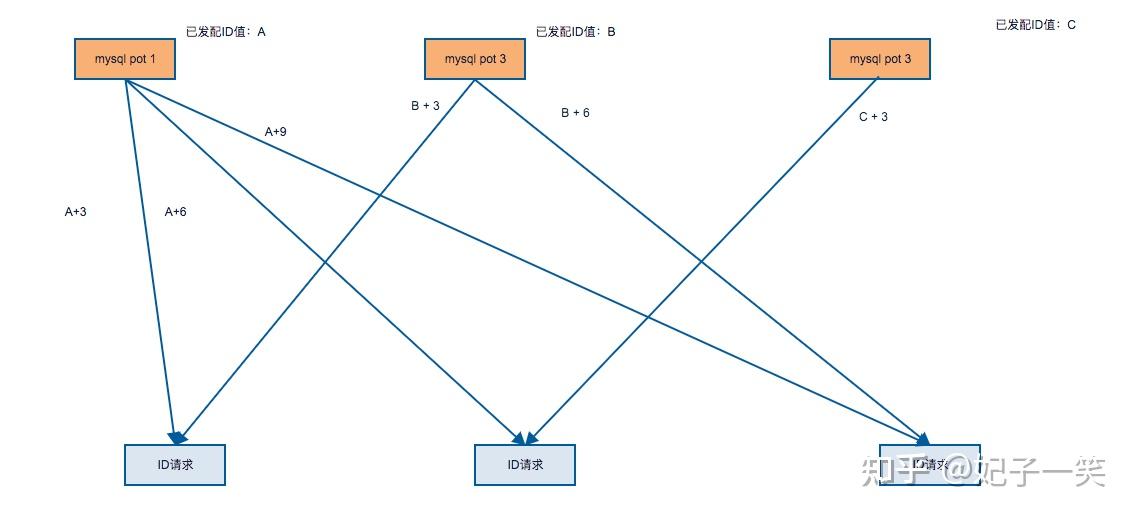
既使节点A崩溃了,只要有一个节点还在,系统就能工作。
但是不太好扩展,如果一开始只分配了3台机器,后面系统达到瓶颈了添加机器,就比较麻烦了。
在分布式系统中,ID往往有很多意义,比如散列,如何精确地的把按ID的查询散列到某台机器上去,因此在一些场景下ID需要包含机器信息,第一类去中心化ID生成器很好的解决了此类问题。
另外,有时候需要从ID知道系统的数据规模,自增的ID能较好的解决此类问题。
从安全角度上看,不同场景下ID应该有不同的表述,避免被外部猜测。比如微信号在第三方服务中是不能被直接使用的,而是一个64字节不具备查询意义的open id。
能不能有一个ID机器既能满足散列,又能反映数据规模呢,我想是可以的。
本来只想分享一下现行的生成规则,作为文章的附加,我简单设计了一个有效的ID生成器。
快速生成,不冲突。既使系统时间被重置,也不会冲突。能从最新的ID拿到当前的数据规模。支持不同场景不同表述。
长度(byte)含义意义4unix epoch到当前的秒数去中心化3机器标识2进程标识3扩展计数8统一分配全局ID中心化
设计上将中心化与去中心化结合,对外展示去中心化的ID, 对内展示全部,对统计展示中心化ID。
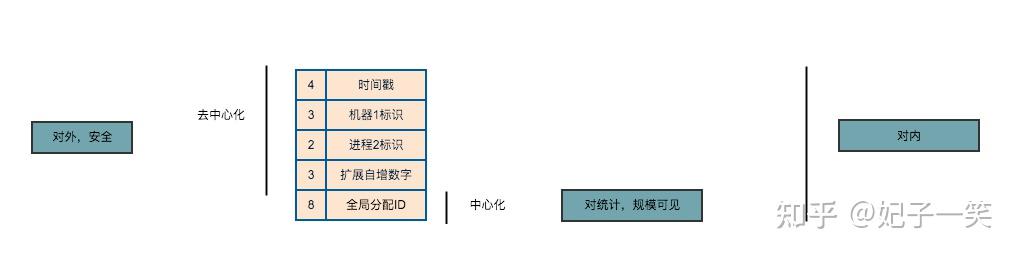
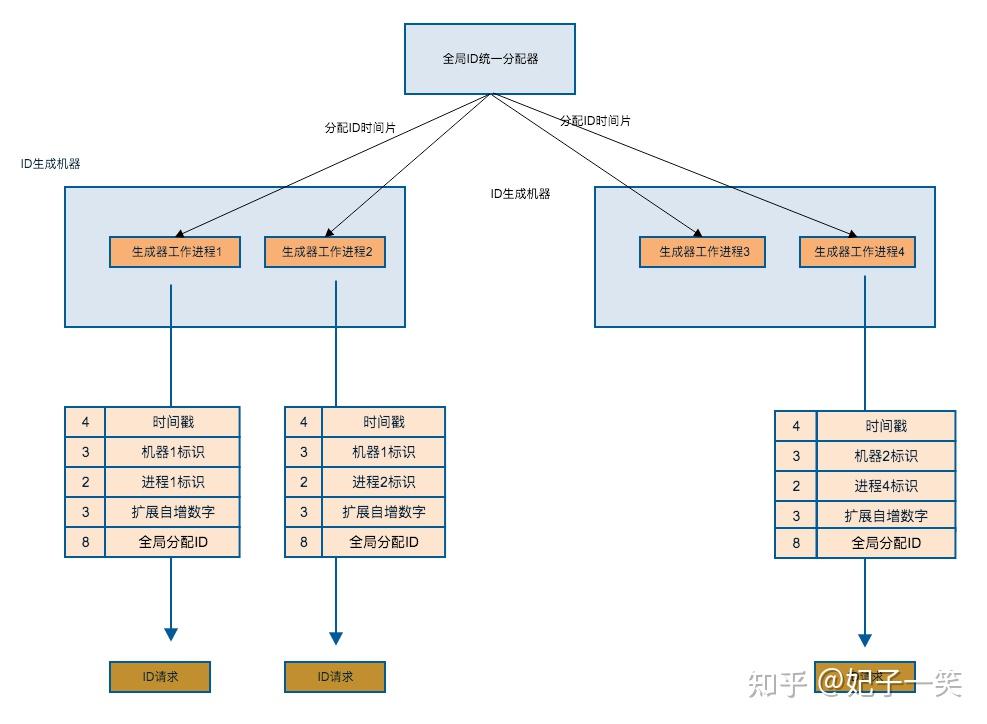
作为中心化的瓶颈,必须由机器保障其功能可靠。
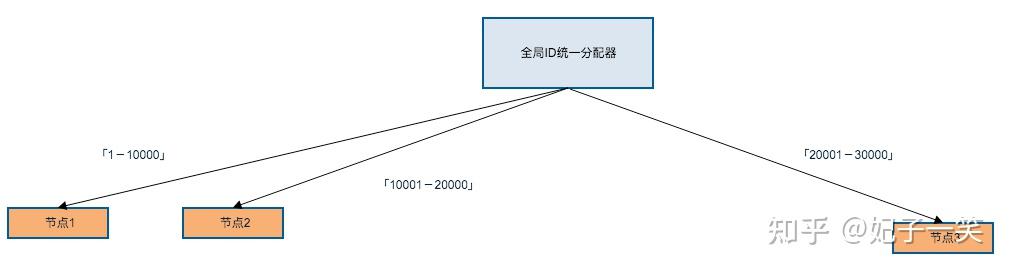
各个节点从全局ID分配器批量获取ID作为预分配资源,当节点剩余预留ID低于阈值时再次申请。
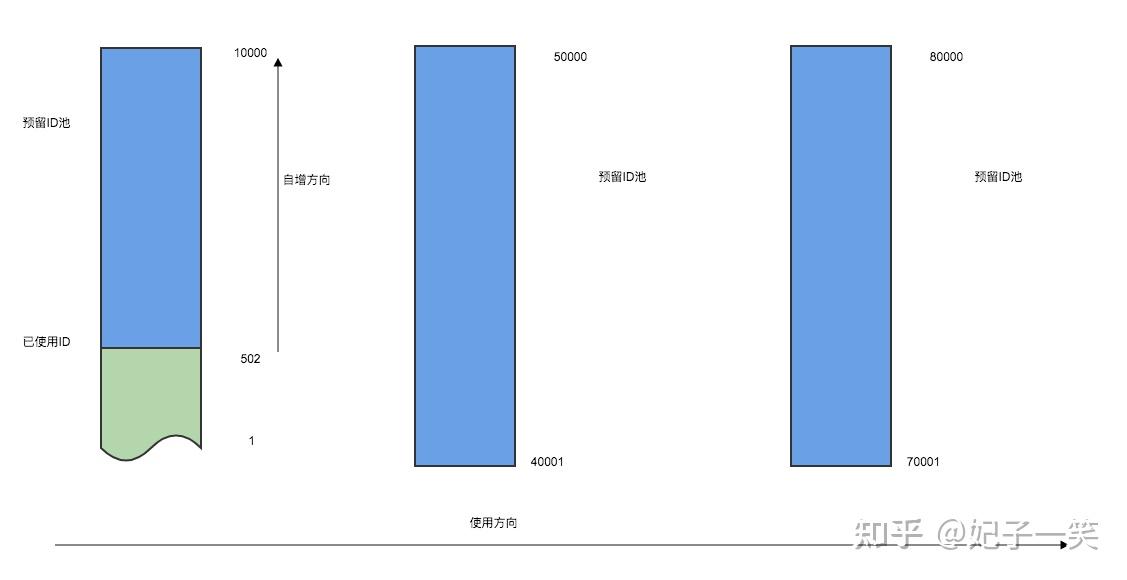
其逻辑非常简单, 以下:
void Pot: nRequest(long& conID, long& reqID){ uint64_t id = cache.incr(); //预留ID自增 if(id <= 0){ //预留ID不够 cache.distribute([this, &conID, &reqID](uint64_t id, uint32_t err){ //请求后端申请全局分配预留片,并设置好回调 this->response(conID, reqID, id); }); //向全局请求分本书 return; } if(cache.shouldDistribute()){ //检查预留池是否达到申请阈值 cache.distribute(); //向后端申请全局分配预留片 } response(conID, reqID, id); //返回 } nRequest(long& conID, long& reqID){ uint64_t id = cache.incr(); //预留ID自增 if(id <= 0){ //预留ID不够 cache.distribute([this, &conID, &reqID](uint64_t id, uint32_t err){ //请求后端申请全局分配预留片,并设置好回调 this->response(conID, reqID, id); }); //向全局请求分本书 return; } if(cache.shouldDistribute()){ //检查预留池是否达到申请阈值 cache.distribute(); //向后端申请全局分配预留片 } response(conID, reqID, id); //返回 }
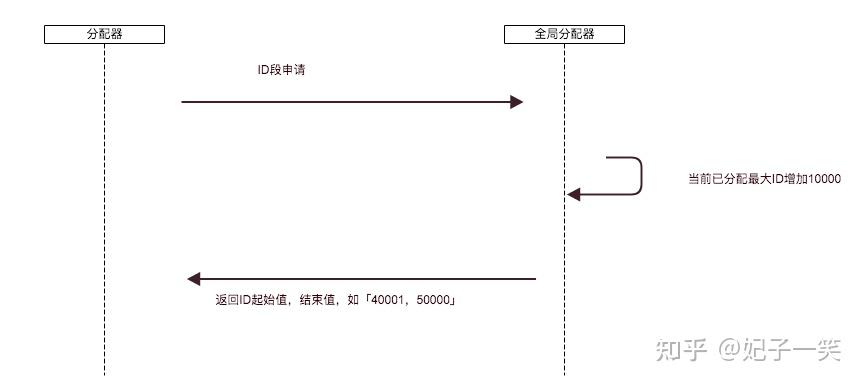
工作原理也是一样简单
void Distribute:nRequest(long& conID, long& reqID){
uint64_t minID, maxID, err;
uint32_t flag = db.pre(minID, maxID, err); //预分配ID片
if(flag <= 0){ //是否出错
response(conID, reqID, err); //返回
return;
}
response(conID, reqID, minID, maxID); //返回ID片
}
单节点崩溃,其他节点仍能崩溃,这个比较简单。
全局分配器的崩溃处理需要在设计上保障,可以同时存在几个全局生成器,且并不缓存当前最大分配ID,该值由数据库来存储。
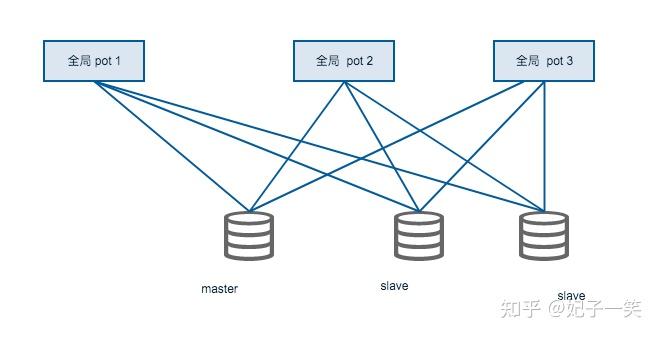
全局分配的请求是个低频处理器。
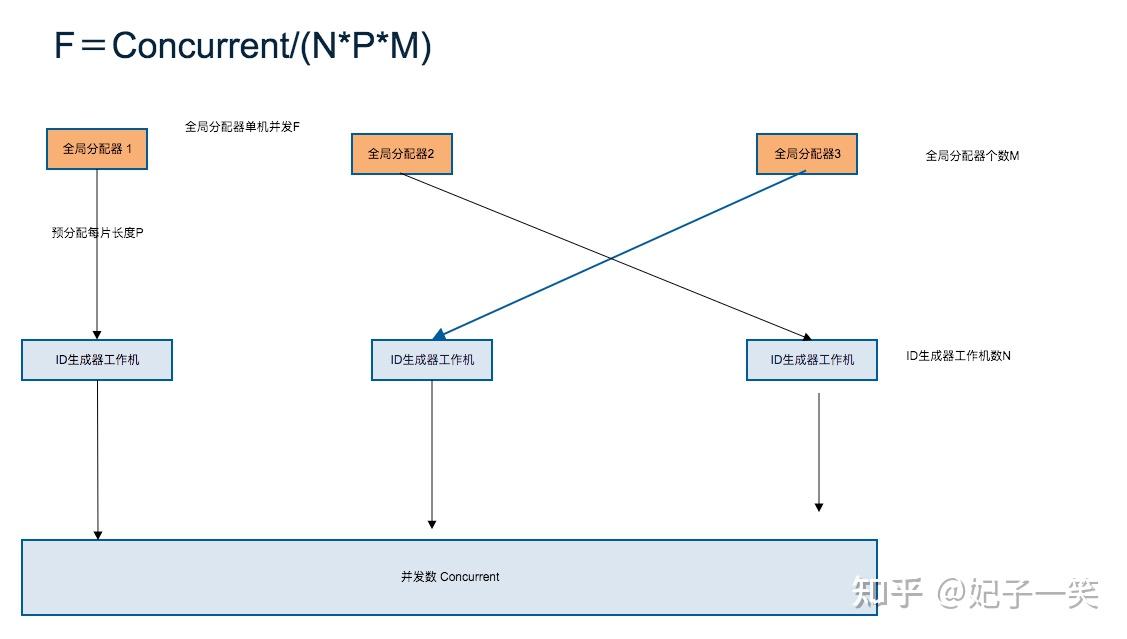
假设工作节点数为N, 系统每秒处理并发为Concurrent, 全局分配器的请求频次F,每次分配ID片长度为P, 全局分配器个数为M,则有下列公式:
F=Concurrent/(NPM)
假设每秒并发数为100万 (1秒产生100万个ID,1秒新增100万个用户,实际不可能),有5个工作节点,全局分配器个数为4, 每次申请ID片为10000。
F=1000,000 / (5 * 10000*4) =5.
100万每秒的分配也只有每秒几次的请求,而且P的值可以灵活修改,假设P=100,000(每片10万个ID),则每秒1个请求都没有了。
这种情况下对全局分配的安全只需要对数据主从热备就行了。
将上面的规则重新审视一下:
含义
字段长度(byte)备注time4unix epoch到当前的秒数去中心化machine3机器标识process2进程标识count3扩展计数center id8统一分配全局ID中心化
如果只有前4个,去掉center id, 系统退化成了mongodb的去中心化ID生成方案。
如果去掉前四项,保留center id,则退化成了具备分布式功能的中心化ID生成方案。
无论是去中心化方案与中心化方案,都能做到百万每秒的响应,且设计简单,冗灾方便。
在一些简单的业务里,二者选其一足矣。
|
|


 发表于 2025-10-29 21:45:07
发表于 2025-10-29 21:45:07